


Publications
Publications
Filter by
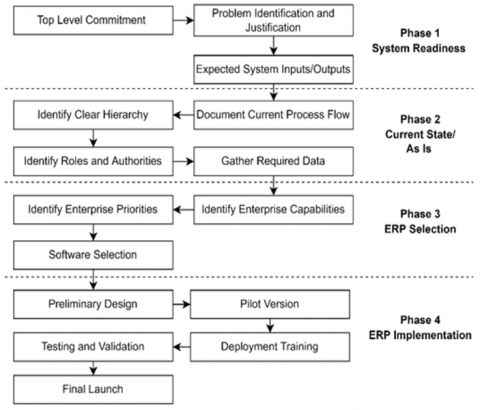
Novel Integrated Framework for ERP Selection and Implementation
As the economic pressure on businesses increases, organizations try to adopt innovative technology solutions to cope with this pressure and adapt to the rapid market changes. Particularly for small and medium enterprises (SMEs). They must integrate all resources and information levels to highly utilize their limited resources and survive the local and global competition. This could be achieved by

Green and Sustainable Packaging Manufacturing: a Case Study of Sugarcane Bagasse-Based Tableware in Egypt
Bagasse-based products contribute to solving the plastic pollution problem. This paper presents an alternative by producing bioplastic products that can be manufactured in many forms ranging across different industries such as food packaging, single use tableware, and crafts. The researchers aim to prove the alternative’s market variability through conducting a feasibility study of establishing a
A review of upper limb robot assisted therapy techniques and virtual reality applications
Impairments in the sensorimotor system negatively impact the ability of individuals to perform daily activities autonomously. Upper limb rehabilitation for stroke survivors and cerebral palsy (CP) children is essential to enhance independence and quality of life. Robot assisted therapy has been a bright solution in the last two decades to promote the recovery process for neurological disorders

Providing a labeled statements dataset to enhance the trans-compilation-based tools
Nowadays Mobile Applications are a necessity as everyone is depending on them in their everyday tasks. We use them for communication, entertainment, and utilities. Every day new devices are introduced to the market. The diversity in these devices resulted in many platforms like Android and iOS. These different mobile platforms used by different companies and manufacturers made it challenging for

SSHC with One Capacitor for Piezoelectric Energy Harvesting
Piezoelectric vibration energy harvesters have attracted a lot of attention as a way to power self-sustaining electronic systems. Furthermore, as part of the growing Internet of Things (loT) paradigm, the ongoing push for downsizing and higher degrees of integration continues to constitute major drivers for autonomous sensor systems. Two of the most effective interface circuits for piezoelectric
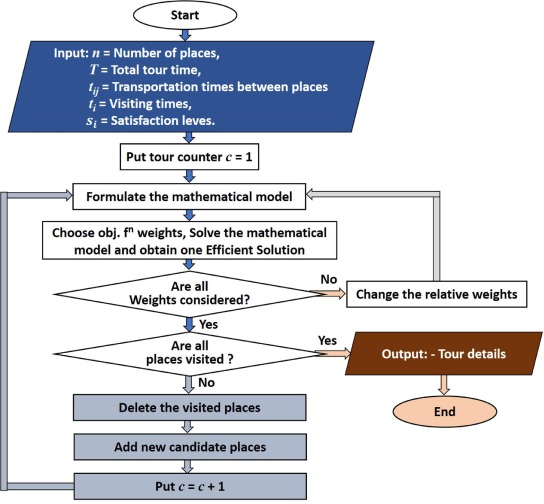
A multiobjective nonlinear combinatorial model for improved planning of tour visits using a novel binary gaining-sharing knowledge- based optimization algorithm
This chapter proposes a novel binary version of recently developed Gaining-Sharing knowledge-based optimization algorithm (GSK) to solve binary optimization problems. GSK algorithm is based on the concept of how humans acquire and share knowledge during their life span. Binary version of GSK named novel binary Gaining-Sharing knowledge-based optimization algorithm (BGSK) depends on mainly two

Improving the Performance of Semantic Text Similarity Tasks on Short Text Pairs
Training semantic similarity model to detect duplicate text pairs is a challenging task as almost all of datasets are imbalanced, by data nature positive samples are fewer than negative samples, this issue can easily lead to model bias. Using traditional pairwise loss functions like pairwise binary cross entropy or Contrastive loss on imbalanced data may lead to model bias, however triplet loss
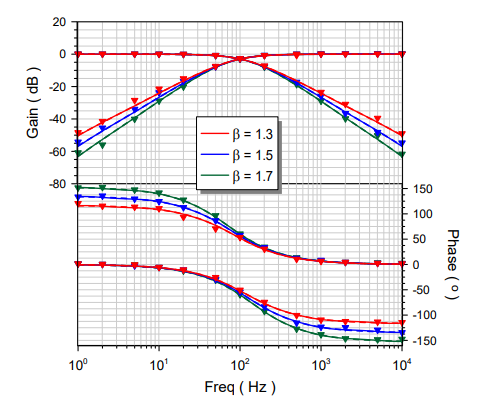
Versatile Field-Programmable Analog Array Realizations of Power-Law Filters
A structure suitable for implementing power-law low-pass and high-pass filter transfer functions is presented in this work. Through the utilization of a field-programmable analog array device, full programmability of the characteristics of the intermediate stages, as is required for realizing the rational integer-order transfer function that approximates the corresponding power-law function, was
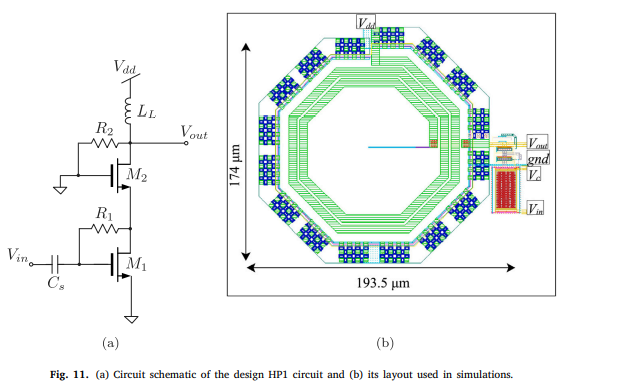
Second-order cascode-based filters
In this paper, we report on the design of a class of analog filters based on the cascode circuit structure surrounded by four impedances. The proposed topology is systematically investigated using two-port network techniques and symbolic math CAD tools. A total of 106 second-order filter circuits can be obtained from this class including 9 low-pass filters, 6 high-pass filters, 73 bandpass filters
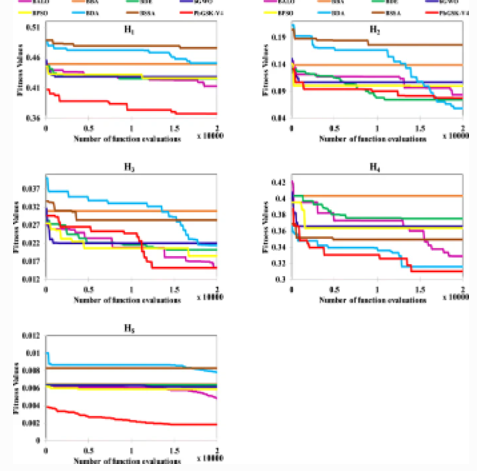
S-shaped and V-shaped gaining-sharing knowledge-based algorithm for feature selection
In machine learning, searching for the optimal feature subset from the original datasets is a very challenging and prominent task. The metaheuristic algorithms are used in finding out the relevant, important features, that enhance the classification accuracy and save the resource time. Most of the algorithms have shown excellent performance in solving feature selection problems. A recently