


Publications
Publications
Filter by
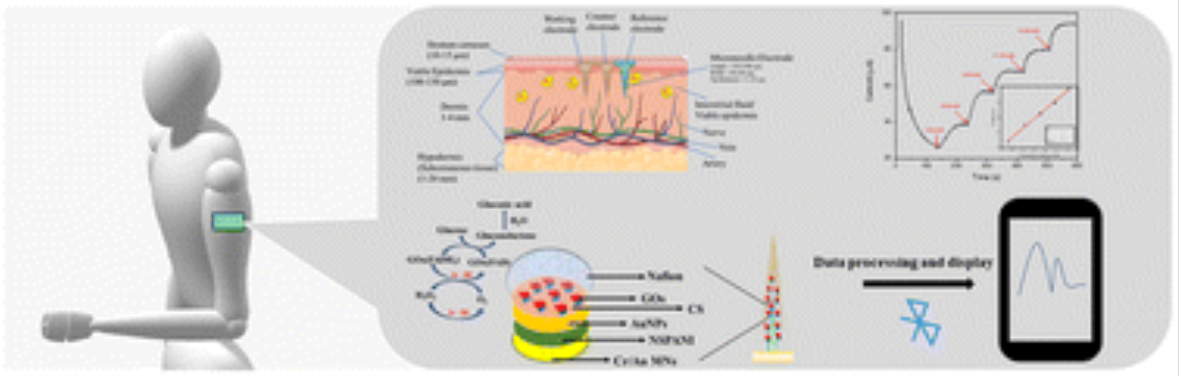
Early detection of hypo/hyperglycemia using a microneedle electrode array-based biosensor for glucose ultrasensitive monitoring in interstitial fluid
Diabetes is a common chronic metabolic disease with a wide range of clinical symptoms and consequences and one of the main causes of death. For the management of diabetes, painless and continuous interstitial fluid (ISF) glucose monitoring is ideal. Here, we demonstrate continuous diabetes monitoring using an integrated microneedle (MN) biosensor with an emergency alert system. MNs are a novel
ArabicQuest: Enhancing Arabic Visual Question Answering with LLM Fine-Tuning
In an attempt to bridge the semantic gap between language understanding and visuals, Visual Question Answering (VQA) offers a challenging intersection of computer vision and natural language processing. Large Language Models (LLMs) have shown remarkable ability in natural language understanding; however, their use in VQA, particularly for Arabic, is still largely unexplored. This study aims to
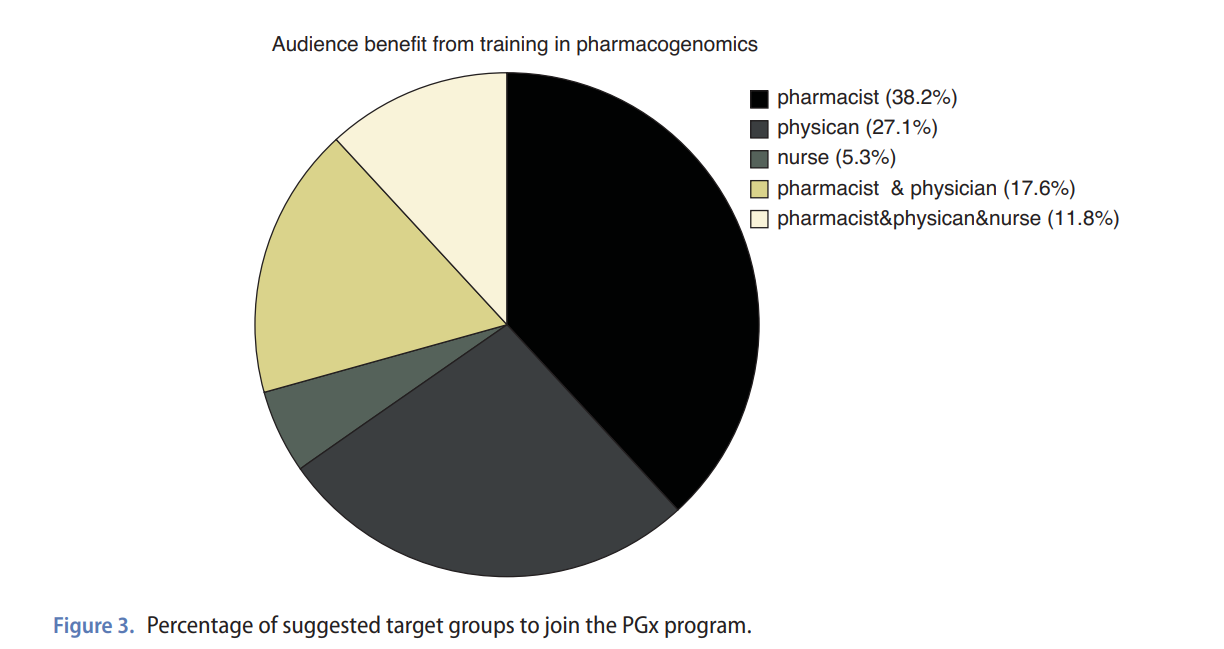
Analysis of the current situation of pharmacogenomics in terms of educational and healthcare needs in Egypt and Lebanon
Pharmacogenomics (PGx) is a practice that investigates the link between genetic differences and drug response in patients. This can improve treatment effectiveness and reduce harmful side effects. However, has yet to be adequately realized in developing nations. Three surveys were conducted between November 2022 to March 2023 in Egypt and Lebanon. The first survey assessed availability of PGx
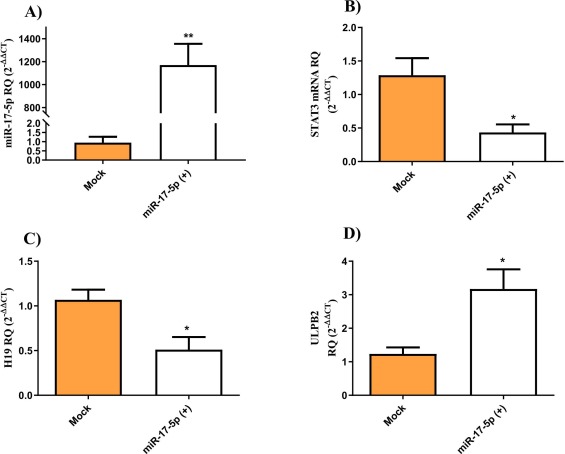
miR-17-5p/STAT3/H19: A novel regulatory axis tuning ULBP2 expression in young breast cancer patients
BACKGROUND AND AIM: UL-16 binding protein 2 (ULBP2) is a highly altered ligand for the activating receptor, NKG2D in breast cancer (BC). However, the mechanism behind its de-regulation in BC patients remains to be explored. The sophisticated crosstalk between miR-17-5p, the lncRNA H19, and STAT3 as a possible upstream regulatory loop for ULBP2 in young BC patients and cell lines remains as an
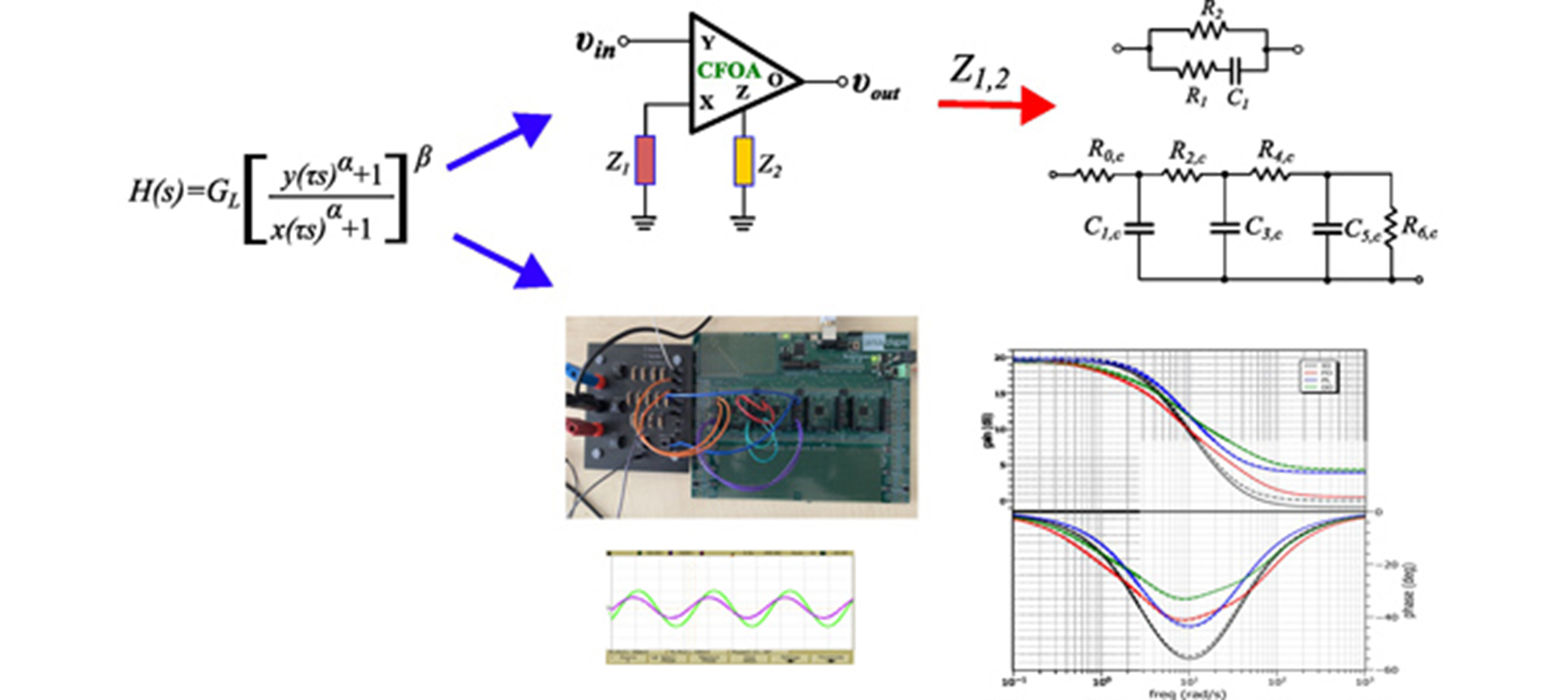
Bilinear Double-Order Filter Designs and Application Examples
A novel kind of non-integer order bilinear filters, named double-order bilinear filters, is introduced in this work. They are based on the employment of two non-integer orders, offering the maximum design flexibility in comparison with their fractional-order and power-law counterparts. An attractive offered benefit is that this is achieved without increasing the circuit complexity, since the
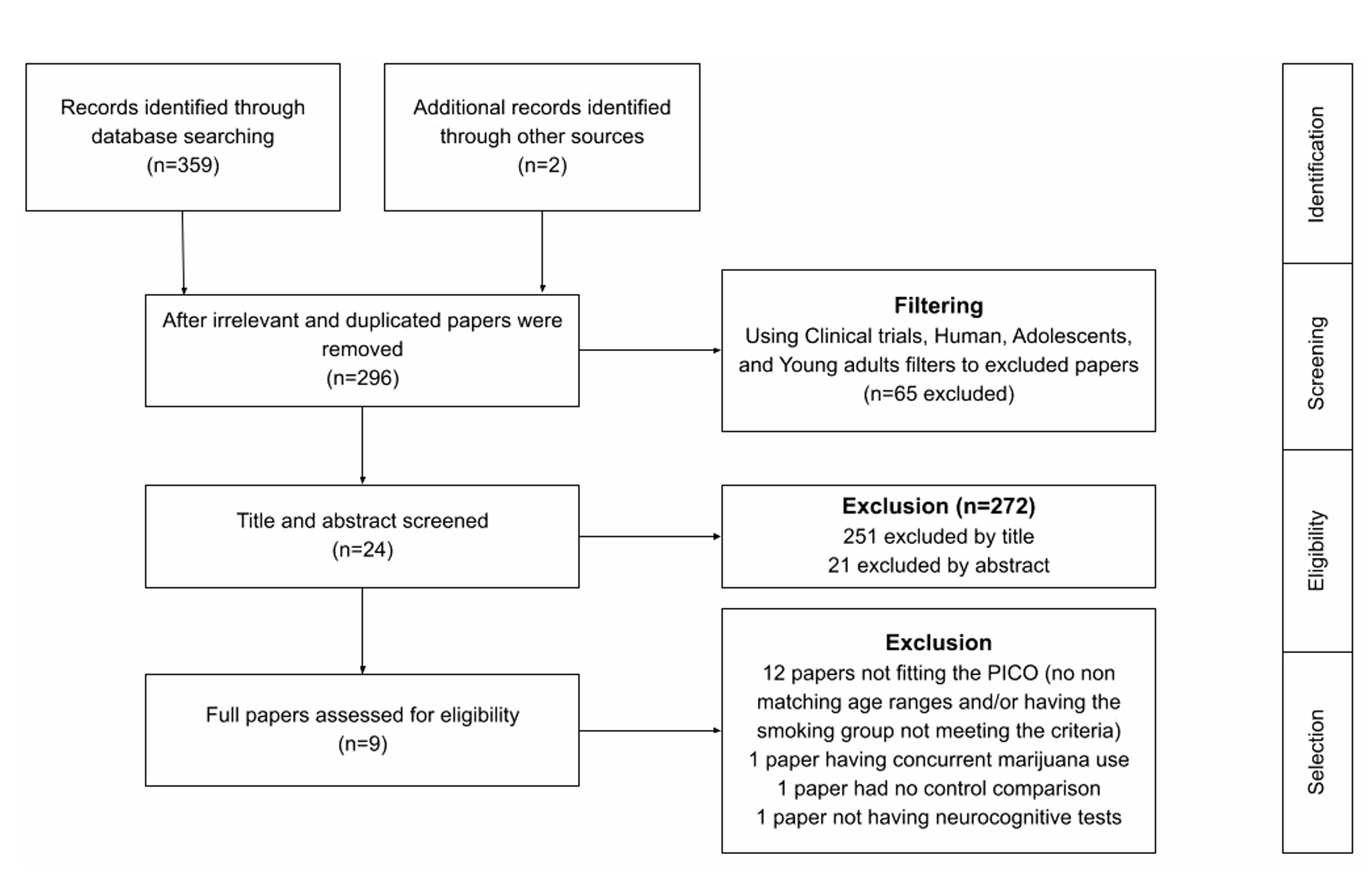
Chronic tobacco smoking and neurocognitive impairments in adolescents and young adults: a systematic review and meta-analysis
There is a lack of robust research investigating the association between neurocognitive impairments and chronic tobacco smoking in adolescents/young adults. Therefore, a systematic review and meta-analysis were conducted to examine this association by pooling cross-sectional studies published from 1980 to 2023. The systematic review assessed the neurocognitive performances between chronic tobacco
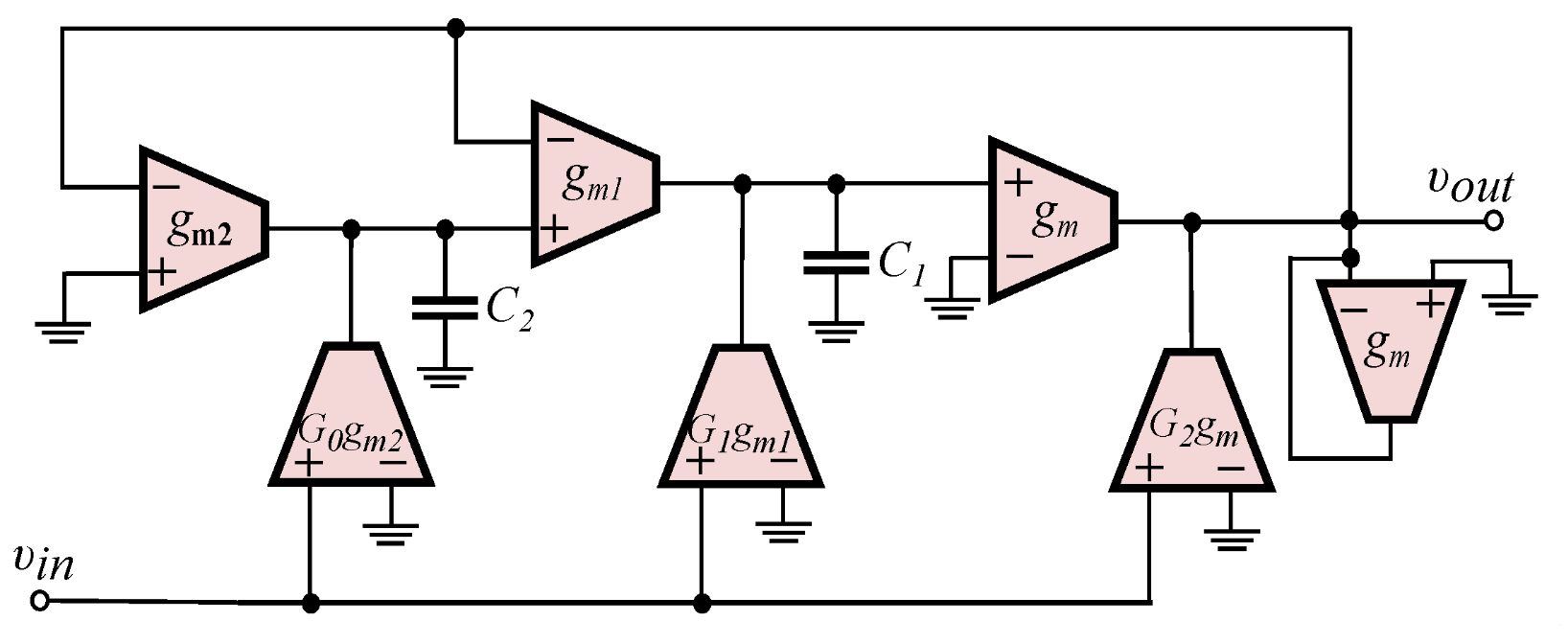
Power-Law Negative Group Delay Filters
A study of the behavior of the power-law negative group delay filters, accompanied by a comparison with their integer-order counterparts, is performed in this work. Employing a curve-fitting based approximation technique, the resulting integer-order rational transfer function is versatile in the sense that it has the same form independent of the order and/or the type of the filter. Its
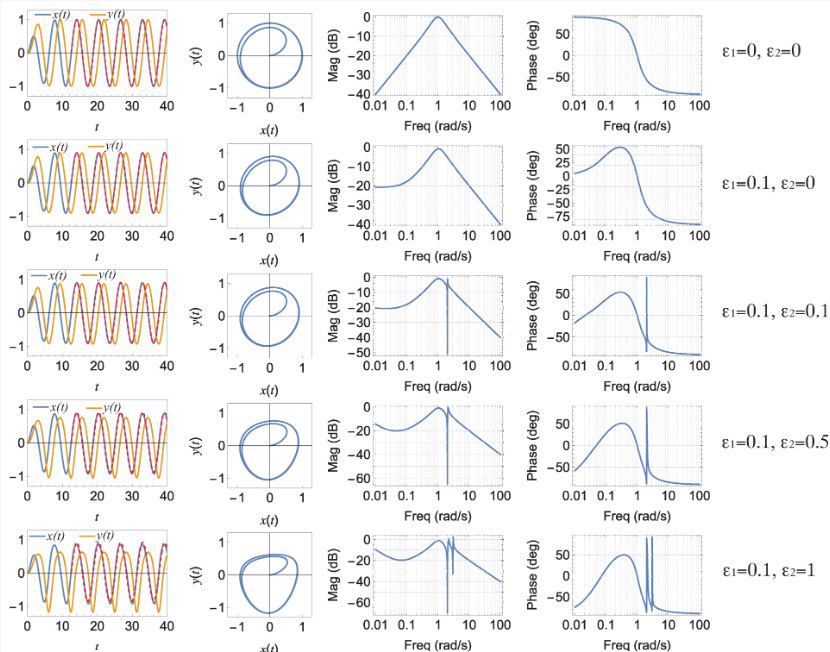
On the Behavior of a Non-Linear Bandpass Filter with Self Voltage-Controlled Resistors
In this work, we explore the behavior of a classical RLC resonance-based bandpass filter, which includes two resistors (one of which is associated with a non-ideal inductor), when either of these resistors is self voltage-controlled. In particular, self-feedback control is achieved by using the voltage developed across the inductor or the capacitor to dynamically change the value of the controlled
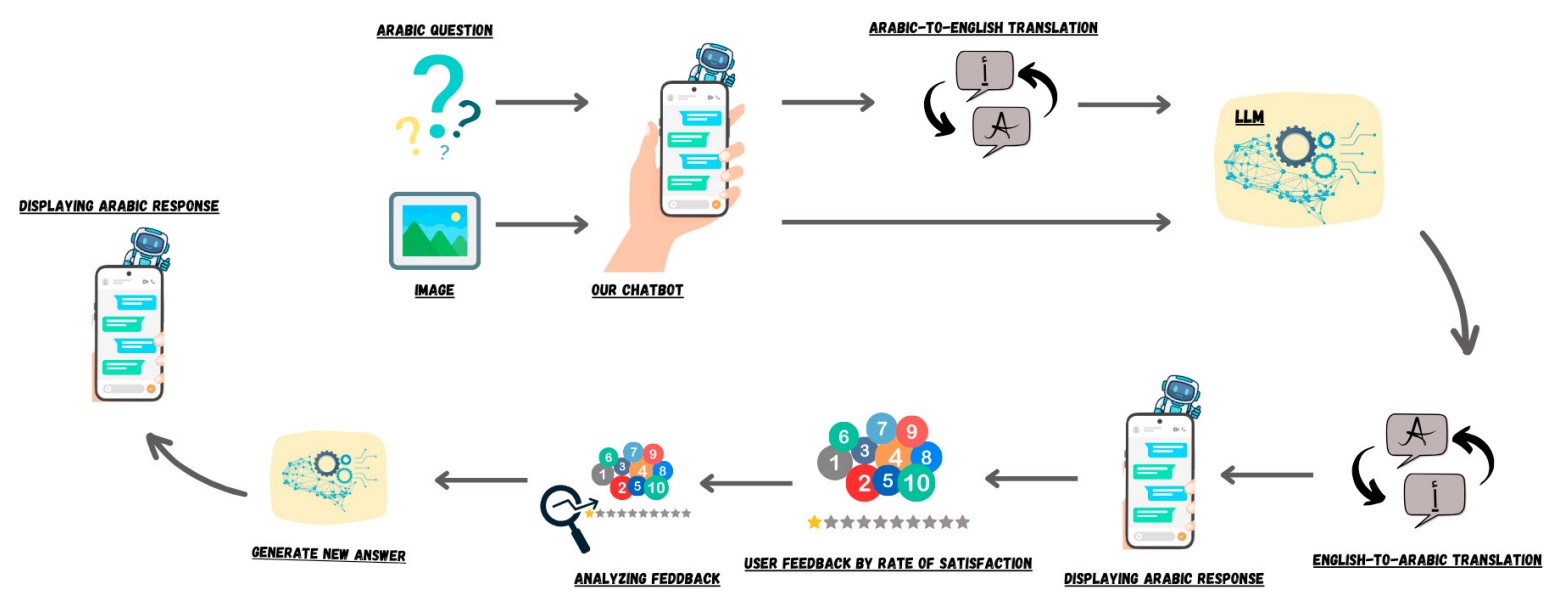
Enhancing Visual Question Answering for Arabic Language Using LLaVa and Reinforcement Learning
Visual Question Answering (VQA) systems have achieved remarkable advancements by combining text-based question answering with image analysis. This integration has resulted in the creating of machines that can comprehend and address questions related to visual content. Despite these technological developments, a notable lack of VQA solutions specifically designed for the Arabic language remains

Retraction Note: Hybrid rough-bijective soft set classification system (Neural Computing and Applications, (2018), 29, 8, (67-78), 10.1007/s00521-016-2711-z)
Retraction to: Neural Comput & Applic (2018) 29:67–78https://doi.org/10.1007/s00521-016-2711-z. The Editor-in-Chief and the publisher have retracted this article. The article was submitted to be part of a guest-edited issue. An investigation by the publisher found a number of articles, including this one, with a number of concerns, including but not limited to compromised editorial handling and